数据库系统
lec1 数据库系统概述
1、什么是数据库
P3
- Data 数据:
- facts and statistics collected together for reference or analysis.收集事实和统计数据以供参考或分析。
- Database 数据库:Data + Base
- A very large, structured collection of data.一个非常大的、结构化的数据集合。
- Models some real-world “enterprise”, such as a university。模拟一些真实世界的“规划”,如大学
- Entities 实体:例如学生、课程
- Relationships 联系:例如张三正在上数据库系统课程。
2、什么是数据库管理系统
P3
- Database Management System (DBMS) 数据库管理系统是:
- A software system designed to store, manage, and facilitate query to databases.一种用于存储、管理和方便查询数据库的软件系统。
- Popular DBMS:Oracle、IBM DB2、Microsoft SQL Server
- Database System = Databases + DBMS 数据库系统 = 数据库 + 数据库管理系统
3、Typical Applications Supported by Database Systems 数据库系统支持的典型应用程序
-
Online Transaction Processing (OLTP) 联机事务处理
- Recording sales data in supermarkets
- Booking flight tickets
- Electronic banking
-
Online analytical processing (OLAP) and Data Warehousing 在线分析处理和数据仓库
- Business reporting for sales data
- Customer Relationship Management (CRM)
-
Is the WWW a DBMS?
- The Web = Surface Web + Deep Web
- Surface Web: simply the HTML pages
- Accessed by “search”:
- Pose keywords in search box.
- Accessed by “search”:
- Deep Web: content hidden behind HTML forms
- Accessed by “query”
- Fill in query forms.
4、搜索和查询的区别
Search is structure-free.Query is structure-aware.搜索是无结构的。查询是结构感知的。
- Search is structure-free.
- The keywords “database systems” can appear in anyplace in a HTML pages
- Query is structure-aware.
- Say, we restruct that the keywords “database systems” can only appear in the “TITLE” field.
- i.e., we assume there is an underlying STRUCTURE (of a book).
5、文件和DBMS的区别
- We can store data in OS files.
- E.g., Google has its own distributed file system called Google File System (GFS).
- What are the advantages of DBMS?
- Good data modeling 好的数据建模
- Data Independence 数据独立性
- Data Integrity and Security 数据完整性和安全性
- Simple and efficient ad-hoc queries 简单高效的即时查询
- Reduced application development time 缩短应用程序开发时间
- Concurrency control 并发控制
- Crash recovery 事故恢复
- Good data modeling 好的数据建模
6、历史视角
P5
- Integrated Data Store (IDS)集成数据存储, by Charles Bachman, early 1960s.网络数据模型,1973年图灵奖获得者。
- Information Management System (IMS)信息管理系统, by IBM, late 1960s.Hierarchical data model.分层数据模型
- Relational Data Model关系数据模型, by Edgar Codd, 1970.1981年图灵奖获得者
- System R R系统,关系型数据库系统, by IBM, started in 1974.Structured Query Language (SQL) 结构化查询语言
- INGRES 数据库, by Berkeley, started in 1974.“Interactive Graphic and Retrieval System”交互式图形检索系统。
- Database Transaction Processing数据库事务处理, mainly by Jim Gray.1993年图灵奖获得者
- Object-Relational DBMS对象关系数据库管理系统, 1990s.
- Stonebraker, Michael with Moore, Dorothy. Object-Relational DBMSs: The Next Great Wave. 1996.
- Postgres (UC Berkeley), PostgreSQL.
- IBM’s DB2, Oracle database, and Microsoft SQL Server
- Turing Award, 2014.
- Column store列存储, memory database内存数据库, big data大数据, 2010s.
- C-store, H-Store, SciDB , …
7、从OLTP到OLAP和数据仓库
- OLAP (On-Line Analytical Processing, Codd, 1993)联机分析处理
- Flexible Reporting for Business Intelligence灵活的商业智能报告
- Characteristics of OLAP applications :
- Transactions that involve large numbers of records 涉及大量记录的事务
- Frequent Ad-hoc queries and Infrequent updates 频繁的特定查询和不频繁的更新
- A few decision making users 少数决策用户
- Fast response times 快速响应时间
- Data warehouses are designed to facilitate reporting and analysis. 促进报告和分析
- Read-Mostly DBMS: C-Store, MonetDB
- Data Warehousing 数据仓库
- Integrated data spanning long time periods, often augmented with summary information. 跨长时间段的集成数据,通常附有摘要信息。
- Several gigabytes to terabytes common. 几GB到TB是常见的。
- Interactive response times expected for complex queries: ad-hoc updates uncommon 复杂查询有预期的交互式响应时间:特别更新不常见
8、Data Mining (DM)数据挖掘
- DM是对大量数据的探索和分析,以发现数据中有效、新颖、潜在有用且最终可理解的模式。
- Association Rules关联规则
- 60%购买尿布的顾客也会购买啤酒。
- 分类:垃圾邮件
- 聚类:按相似兴趣对新浪微博用户进行聚类
- 网页排名:谷歌的PageRank
9、Big Data 大数据
- 牛津字典:太大、太复杂,无法使用标准方法或工具进行操作或查询的数据集。
- 数据来自各个地方
- Big data spans four dimensions: 大数据包括四个维度
- Volume, terabytes (TB), even petabytes of information 容量,TB,甚至PB的信息
- Velocity, Sometimes 2 minutes is too late 速度
- Variety, Big data is any type of data - structured and unstructured data 多样性,大数据是任意类型的数据——结构化和非结构化数据
- Veracity 真实性
10、Describing Data: Data Models 描述数据:数据模型
P8
- A data model is a collection of concepts for describing data. 数据模型是用于描述数据的概念集合。
- A schema is a description of a particular collection of data, using a given data model. 模式是使用给定数据模型对特定数据集合的描述。
- The relational data model is the most widely used model today. 关系数据模型是当今应用最广泛的模型。
- Main concept: relation, basically a table with rows and columns. 关系,基本上是一个包含行和列的表。
- Every relation has a schema, which describes the columns, or fields (their names, types, constraints, etc.). 每个关系都有一个模式,它描述列或字段(它们的名称、类型、约束等)。
11、Schema in Relation Data Model 关系数据模型中的模式
P8
A relation schema is a TEMPLATE of the corresponding relation. 关系模式是对应关系的模板。
12、Levels of Abstraction in a DBMS 数据库管理系统中的抽象层次
P9
- Many views describe how users see the data. 许多场景描述用户如何查看数据。
- Personalized access of data. 个性化数据访问。
- Conceptual schema defines logical structure 概念模式定义了逻辑结构
- i.e., what relations to store. 例如,存储什么关系。
- Physical schema specifies physical structure. 物理模式指定物理结构。
- How the “logical” relations are physically stored on external storage such as disk. 如何将“逻辑”关系物理存储在外部存储器(如磁盘)上。
View外模式->Conceptual schema概念模式->Physical schema物理模式->DB磁盘
Example: University Database
- Conceptual schema:
- Students(sid: string, name: string, login: string, age: integer, gpa: real)
- Courses(cid: string, cname: string, credits: integer)
- Enrolled(sid: string, cid: string, grade: string)
- Physical schema:
- Relations stored as unordered files.
- Index on first column of Students.
- External Schema (View):
- Course_info(cid: string, enrollment: integer)
13、Data Independence 数据独立性
P11
- Applications insulated from how data is structured and stored. 应用程序与数据的结构和存储方式无关。
- Logical data independence: Protection from changes in logical structure of data. 逻辑数据独立性:防止数据的逻辑结构发生变化。
- Physical data independence: Protection from changes in physicalstructure of data. 物理数据独立性:防止数据的物理结构发生变化。
- One of the most important benefits of using a DBMS!
14、Queries in a Relational DBMS 关系数据库管理系统中的查询
P11
- Specified in a Non-Procedural way 以非程序方式指定
- Users only specify what data they need; 用户只指定他们需要什么数据;
- A DBMS takes care to evaluate queries as efficiently as possible. DBMS会尽可能高效地评估查询。
- a Non-Procedural Query Language: 非过程查询语言:
- SQL: Structured Query Language 结构化查询语言
15、Concurrent execution of user programs 用户程序的并发执行
P13
Why?
- Utilize CPU while waiting for disk I/O 在等待磁盘I/O时利用CPU
- (database programs make heavy use of disk)
- Avoid short programs waiting behind long ones 避免短程序在等待长程序执行完之后再执行
- e.g. ATM withdrawal while bank manager sums balance across all accounts
Concurrent execution 并行执行
- Interleaving actions of different user programs can lead to inconsistency: 不同用户程序的交叉操作可能导致不一致
Concurrency Control 并发控制
- DBMS ensures such problems don’t arise.
- Users can pretend they are using a single-user system. 用户可以当作使用单用户系统。
16、Key concept: Transaction 关键概念:事务
P12
- An Transaction is an atomic sequence of database actions (reads / writes) 事务是数据库操作(读/写)的原子序列
- Each transaction, executed completely, must leave the DB in a consistent state if DB is consistent when the transaction begins. 如果事务开始时DB是一致的,则完全执行的每个事务都必须使DB保持一致状态。
17、Incomplete Transaction and System Crashes 未完成的事务和系统崩溃
P13
- Incomplete transaction 未完成的事务
- Canceled by the transaction or DBMS 被事务或DBMS取消
- Aborted unexpectedly by system crash 由于系统崩溃而意外中止
- Idea: Keep a log (history) of all actions carried out by the DBMS while executing a set of transactions: 在执行一组事务时,保留DBMS执行的所有操作的日志(历史记录)
- Before a change is made to the database, the corresponding log entry is forced to a safe location. (WAL protocol; OS support for this is often inadequate.) 在对数据库进行更改之前,会将相应的日志条目强制放到安全位置(预写式协议;操作系统对此的支持通常是不够的)
- After a crash, the effects of partially executed transactions are undone using the log. 崩溃后,部分执行的事务的效果将使用日志撤消。
18、数据库管理系统的结构
P14
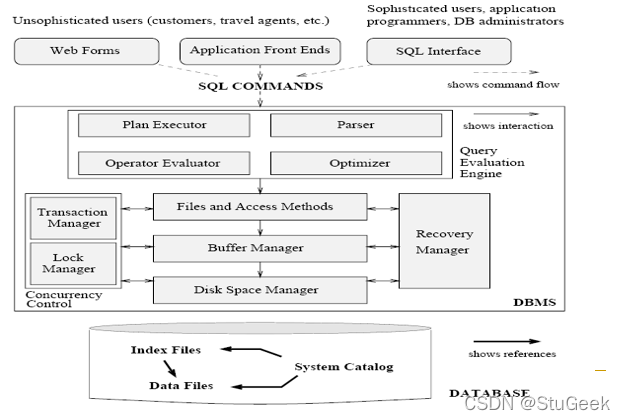
Databases make these folks happy 数据库让这些人很开心
P15
- End users and DBMS vendors 终端用户和DBMS供应商
- DB application programmers 数据库应用程序程序员
- E.g., smart webmasters 网站管理员
- Database administrator (DBA) 数据库管理员
- Designs logical /physical schemas 设计逻辑/物理模式
- Handles security and authorization 处理安全和授权
- Data availability, crash recovery 数据可用性、崩溃恢复
- Database tuning as needs evolve 根据需要调整数据库
- Must understand how a DBMS works! 必须了解DBMS是如何工作的!
19、Summary 总结
- DBMS used to maintain, query large datasets. DBMS用于维护、查询大型数据集
- Benefits include recovery from system crashes, concurrent access, quick application development, data integrity and security. 好处包括从系统崩溃中恢复、并发访问、快速应用程序开发、数据完整性和安全性。
- Levels of abstraction give data independence. 抽象级别提供了数据独立性。
- A DBMS typically has a layered architecture. DBMS通常具有分层体系结构。
- DBAs hold responsible jobs and are well-paid! DBA拥有负责任的工作,而且薪水很高!
- DBMS R&D is one of the broadest, most exciting areas in CS. DBMS研发是CS中最广泛、最令人兴奋的领域之一。
- We focus on Relational DBMS: 我们主要关注关系型DBMS:
- maintain/query structured data 维护/查询结构化数据
lec2 关系模型 The Relational Model
1、关系模型定义
P43-45
- Relational database: 关系数据库
- a set of relations. 一组关系
- Relation: made up of 2 parts:
- Schema模式: specifies name of relation, plus name and type of each column. 指定关系的名称,加上每个列的名称和类型。
- Instance实例: a table, with rows and columns. 具有行和列的表。
- #rows = cardinality行=基
- #fields = arity (or degree)字段=参数数量(或度)
- Can think of a relation as a set of rows or tuples. 可以将关系视为一组行或元组。
- i.e., all rows are distinct 例如,所有行都是不同的
2、SQL - A language for Relational DBs
P45
- SQL (a.k.a. “Sequel”), standard language 标准语言
- Data Definition Language (DDL) 数据定义语言
- create, modify, delete relations 创建、修改、删除关系
- specify constraints 指定约束条件
- administer users, security, etc. 管理用户、安全等。
- Data Manipulation Language (DML) 数据操作语言
- Specify queries to find tuples that satisfy criteria 指定查询以查找满足条件的元组
- add, modify, remove tuples 添加、修改、删除元组
CREATE TABLE ( , … )
INSERT INTO ()
VALUES ()
DELETE FROM
WHERE
UPDATE
SET =
WHERE
SELECT
FROM
WHERE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3、Creating Relations in SQL 创建关系
P45
CREATE TABLE Students
(sid CHAR(20),
name CHAR(20),
login CHAR(10),
age INTEGER,
gpa FLOAT)
- 1
- 2
- 3
- 4
- 5
- 6
创建表格
CREATE TABLE Enrolled
(sid CHAR(20),
cid CHAR(20),
grade CHAR(2))
- 1
- 2
- 3
- 4
添加和删除元组
INSERT INTO Students (sid, name, login, age, gpa)
VALUES ('53688', 'Smith', 'smith@ee', 18, 3.2)
- 1
- 2
DELETE
FROM Students S
WHERE S.name = 'Smith'
- 1
- 2
- 3
4、Keys 键
P47
- Keys are a way to associate tuples in different relations. 键是在不同关系中关联元组的一种方法。
- Keys are one form of integrity constraint (IC) 键是完整性约束(IC)的一种形式
5、Primary Keys 主键
- A set of fields is a superkey if 一组字段是超键:
- No two distinct tuples can have same values in all key fields 没有两个不同的元组可以在所有键字段中具有相同的值
- A set of fields is a key for a relation if 一组字段是关系的键:
- It is a superkey
- No subset of the fields is a superkey. (i.e., minimal). 字段的任何子集都不是超级键
- what if more than one keys for a relation?
- One of the keys is chosen (by DBA) to be the primary key. DBA选择其中一个键作为主键。
- Other keys are called candidate keys. 其他键称为候选键
- E.g.
- sid is a key for Students.
- What about name?
- The set {sid, gpa} is a superkey.
6、Primary and Candidate Keys in SQL SQL中的主键和候选键
P47
- Possibly many candidate keys (specified using UNIQUE), one of which is chosen as the primary key. 可能有许多候选键(使用UNIQUE指定),其中一个被选为主键。
- Keys must be used carefully!
- “For a given student and course, there is a single grade.”
CREATE TABLE Enrolled
(sid CHAR(20)
cid CHAR(20),
grade CHAR(2),
PRIMARY KEY (sid,cid))
VS.
CREATE TABLE Enrolled
(sid CHAR(20),
cid CHAR(20),
grade CHAR(2),
PRIMARY KEY (sid),
UNIQUE (cid, grade))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- “Students can take only one course, and no two students in a course receive the same grade.”
7、Foreign Keys 外键 vs. Referential Integrity 参照完整性
P48
-
Foreign key: Set of fields in one relation that is used to `refer’ to a tuple in another relation. 一个关系中的一组字段,用于“引用”另一个关系中的元组。
- Must correspond to the primary key of the other relation. 必须对应于其他关系的主键。
- Like a `logical pointer’.
-
If all foreign key constraints are enforced, referential integrity is achieved (i.e., no dangling references.) 如果强制执行所有外键约束,则实现参照完整性(即,没有悬空引用)
-
E.g. Only students listed in the Students relation should be allowed to enroll for courses. 只有学生关系中列出的学生才允许注册课程。
- sid is a foreign key referring to Students: sid是指向学生关系的外键
CREATE TABLE Enrolled
(sid CHAR(20),cid CHAR(20),grade CHAR(2),
PRIMARY KEY (sid,cid),
FOREIGN KEY (sid) REFERENCES Students )
- 1
- 2
- 3
- 4
8、Enforcing Referential Integrity 强制引用完整性
P51
- sid in Enrolled: foreign key referencing Students. sid是指向学生关系的外键
- Scenarios:
- Insert Enrolled tuple with non-existent student id? 向Enrolled中插入不存在的学生学号的元组
- Delete a Students tuple? 删除一个学生元组
- Also delete Enrolled tuples that refer to it? (Cascade) 级联
- Disallow if referred to? (No Action) 不采取行动
- Set sid in referring Enrolled tuples to a default value? (Set Default) 设置默认值
- Set sid in referring Enrolled tuples to null, denoting
unknown’ orinapplicable’. (Set NULL) 设置为空
- Similar issues arise if primary key of Students tuple is updated. 如果更新Students元组的主键,也会出现类似的问题
9、Integrity Constraints (ICs) 完整性约束
P46
- IC: condition that must be true for any instance of the database 对于数据库的任何实例都必须为真的条件
- e.g., domain constraints. 域约束。
- ICs are specified when schema is defined. 在定义模式时指定ICs
- ICs are checked when relations are modified. 修改关系时会检查ICs
- A legal instance of a relation is one that satisfies all specified ICs. 一个关系的合法实例是满足所有指定ICs的实例
- DBMS should not allow illegal instances. DBMS不应该允许非法实例
- If the DBMS checks ICs, stored data is more faithful to real-world meaning. 如果DBMS检查ICs,则存储的数据更符合真实世界的含义
- Avoids data entry errors, too! 避免数据也输入错误
10、Where do ICs Come From?
- Semantics 语义学 of the real world!
- Key and foreign key ICs are the most common 键和外键ICs是最常见的
- More general ICs supported too. 也支持更通用的ICs
11、Relational Query Languages 关系查询语言
- Feature: Simple, powerful ad hoc querying 简单、功能强大的即时查询
- Declarative languages 说明性语言
- Queries precisely specify what to return 查询精确地指定要返回的内容
- DBMS is responsible for efficient evaluation (how). DBMS负责有效的评估
- Allows the optimizer to extensively re-order operations, and still ensure that the answer does not change. 允许优化器广泛地重新排序操作,并且仍然确保答案不变。
- Key to data independence! 数据独立性关键
The SQL Query Language SQL查询语言
- The most widely used relational query language.
- Current std is SQL:2008; SQL92 is a basic subset
- To find all 18 year old students, we can write:
SELECT *
FROM Students S
WHERE S.age=18
- 1
- 2
- 3
- To find just names and logins, replace the first line:
SELECT S.name, S.login
- 1
Querying Multiple Relations 查询多个关系
- What does the following query compute
SELECT S.name, E.cid
FROM Students S, Enrolled E
WHERE S.sid=E.sid AND E.grade='A'
- 1
- 2
- 3
12、Semantics of a Query 查询的语义
- A conceptual evaluation method for the previous query: 之前的查询的概念评估方法:
- do FROM clause: compute cross-product of Students and Enrolled 计算学生和注册课程的叉积
- do WHERE clause: Check conditions, discard tuples that fail 检查条件,丢弃不要的元组
- do SELECT clause: Delete unwanted fields 删除不需要的字段
- Remember, this is conceptual. Actual evaluation will be much more efficient, but must produce the same answers. 记住,这是概念性的。实际评估将更加有效,但必须得出相同的答案。
13、Summary 总结
- A tabular representation of data, simple and intuitive, currently the most widely used 数据的表格表示,简单直观,目前使用最广泛
- Object-relational features in most products 大多数产品中的对象关系特性
- Integrity constraints can be specified by the DBA, based on application semantics. DBMS checks for violations. 完整性约束可以由DBA根据应用程序语义指定。DBMS检查违规行为。
- Two important ICs: primary and foreign keys 主键和外键
- In addition, we always have domain constraints. 域约束
- Powerful query languages exist.
- SQL is the standard commercial one SQL是一种标准商用语言
- DDL - Data Definition Language 数据定义语言
- DML - Data Manipulation Language 数据操作语言
- SQL is the standard commercial one SQL是一种标准商用语言
lec3 关系代数 Relational Algebra
1、Formal Relational Query Languages 形式关系查询语言
P74
- Relational Algebra: More operational, very useful for representing execution plans. 关系代数:更具操作性,对于表示执行计划非常有用。
- Relational Calculus: Describe what you want, rather than how to compute it. (Non-procedural, declarative.) 关系演算:描述你想要什么,而不是如何计算它。(非程序性、说明性。)
Preliminaries
- A query is applied to relation instances 查询应用于关系实例
- The result of a query is also a relation instance. 查询的结果也是一个关系实例。
- Schemas of input relations for a query are fixed 查询的输入关系模式是固定的
- Schema for the result of a query is also fixed. 查询结果的模式也是固定的。
- determined by the query language constructs 由查询语言构造确定
- Positional vs. named-field notation 位置与命名字段表示法:
- Positional notation easier for formal definitions 位置表示法便于形式化定义
- Named-field notation more readable. 命名字段表示法更具可读性。
- Both used in SQL 两者都用于SQL
- Though positional notation is discouraged 虽然不鼓励使用位置表示法
2、Relational Algebra: 5 Basic Operations 关系代数:5种基本运算
- Selection ( σ ) 选择(选行)
- Selects a subset of rows (horizontal) 选择行的子集(水平)
- Projection ( π ) 投影(选列)
- Retains only desired columns (vertical) 仅保留所需的列(垂直)
- Cross-product ( × ) 叉乘/拼表
- Allows us to combine two relations.
- Set-difference ( — ) 差/减表
- Tuples in r1, but not in r2.
- Union ( ∪ ) 并表
- Tuples in r1 or in r2.
- Since each operation returns a relation, operations can be composed! (Algebra is “closed”.)
Projection ( π ) 投影
P76
- Example:
- Retains only attributes that are in the “projection list”. 仅保留“投影列表”中的属性。
- Schema of result: 结果模式
- the fields in the projection list 投影列表中的字段
- with the same names that they had in the input relation. 与输入关系中的名称相同
- Projection operator has to eliminate duplicates 必须消除重复项
- Note: real systems typically don’t do duplicate elimination 实际系统通常不进行重复消除
- Unless the user explicitly asks for it. 除非用户明确要求
- (Why not?)
Selection ( σ ) 选择
P76
- Selects rows that satisfy selection condition. 选择满足选择条件的行
- Result is a relation. 结果是一种关系
- Schema of result is same as that of the input relation. 结果的模式与输入关系的模式相同
- Do we need to do duplicate elimination?
Union and Set-Difference 并差
P77
- Both of these operations take two input relations, which must be union-compatible: 这两种操作都采用两种输入关系,它们必须是并集兼容的
- Same number of fields. 相同数量的字段
- ‘Corresponding’ fields have the same type. “对应”字段具有相同的类型
- For which, if any, is duplicate elimination required?
Cross-Product 叉积
P78
- S1 × R1:
- Each row of S1 paired with each row of R1. S1的每一行与R1的每一行配对
- Q: How many rows in the result?
- Result schema has one field per field of S1 and R1, 结果牧师在S1和R1的每个字段中有一个字段
- Field names `inherited’ if possible. 如果可能,字段名“继承”
- Naming conflict: S1 and R1 have a field with the same name. 命名冲突:S1和R1有一个同名字段
- Can use the renaming operator: 可以使用重命名运算符
重命名 ρ
P78
Compound Operator: Intersection 交
P77
- On top of 5 basic operators, several additional “Compound Operators” 除5个基本运算符外,还有几个“复合运算符”
- These add no computational power to the language 这些不增加语言的计算能力 有用的速记
- Useful shorthand 可以用基本运算符单独表示
- Can be expressed solely with the basic operators. 交集采用两个输入关系,它们必须是并集兼容的
- Intersection takes two input relations, which must be union-compatible.
- Q: How to express it using basic operators? 问:如何使用基本运算符表示它?
- R ∩ S = R - (R - S)
Compound Operator: Join 连接
P78
- Involve cross product, selection, and (sometimes) projection. 涉及叉积、选择和(有时)投影。
- Most common type of join: “natural join” 最常见的连接类型:“自然连接”
- R |X| S conceptually is:
- Compute R × S 计算R×S
- Select rows where attributes appearing in both relations have equal values 选择两个关系中出现的属性值相等的行
- Project all unique attributes and one copy of each of the common ones. 投影所有唯一属性和每个公共属性的一个副本
- R |X| S conceptually is:
- Note: Usually done much more efficiently than this. 注意:通常完成比这更高效
Other Types of Joins
- Condition Join (or “theta-join”) 条件连接 :
P79
Result schema same as that of cross-product. 结果模式与叉积的结果模式相同。
May have fewer tuples than cross-product. 可能具有比叉积更少的元组。
Equi-Join 等值连接 : Special case: condition c contains only conjunction of equalities. 特例:条件c只包含等式的连接。
例子
P81



Summary 总结
- Relational Algebra: a small set of operators mapping relations to relations 关系代数:将关系映射到关系的一小组运算符
- Operational, in the sense that you specify the explicit order of operations 可操作性,即指定操作的显式顺序
- A closed set of operators! Can mix and match. 一组闭合的运算符!可以混搭。
- Basic ops include: σ, π, x, ∪, -,|X|
- Important compound ops: ∩,
lec3 Storing Data: Disks and Files 存储数据:磁盘和文件
Block diagram of a DBMS 数据库管理系统的框图
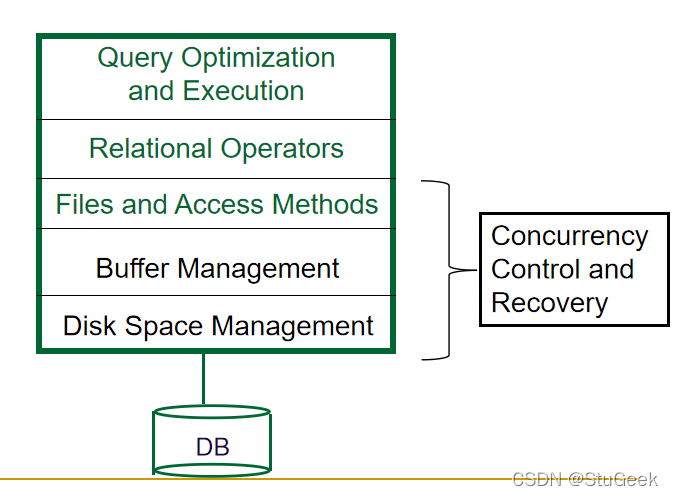
Disks, Memory, and Files 磁盘、内存和文件

Disks and Files 磁盘和文件
- DBMS stores information on disks. DBMS将信息存储在磁盘上。
- Tapes are also used. 还使用磁带。
- Major implications for DBMS design! DBMS设计的主要含义!
- READ: transfer data from disk to main memory (RAM). 读取:将数据从磁盘传输到主存储器(RAM)。
- WRITE: transfer data from RAM to disk. 写入:将数据从RAM传输到磁盘。
- Both high-cost relative to memory references 两者都比内存引用成本高
- Can/should plan carefully! 可以/应该仔细计划!
Why Not Store Everything in Main Memory? 为什么不把所有东西都存储在主内存中呢?
- Costs too much. For ~$1000, PCConnection will sell you either 费用太高了。只需约1000美元,PCConnection即可向您出售
- ~80GB of RAM (unrealistic) ~80GB内存(不切实际)
- ~400GB of Flash USB keys (unrealistic) 约400GB闪存USB密钥(不现实)
- ~180GB of Flash solid-state disk (serious) ~180GB闪存固态磁盘(严重)
- ~7.7TB of disk (serious) 约7.7TB磁盘(严重)
- Main memory is volatile. 主存储器是易失性的。
- Want data to persist between runs. (Obviously!) 希望数据在两次运行之间保持不变。(显然!)
The Storage Hierarchy 存储层次结构
P231
- Main memory (RAM) for currently used data. 用于当前使用数据的主存储器(RAM)。
- Disk for main database (secondary storage). 主数据库磁盘(辅助存储)
- Tapes for archive (tertiary storage). 用于存档的磁带(第三级存储)
- The role of Flash (SSD) still unclear 闪存(SSD)的作用仍不清楚
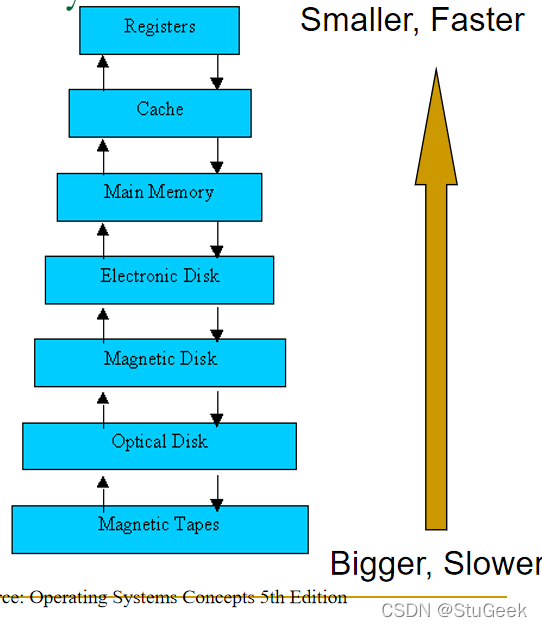
Disks 磁盘
P231
- Still the secondary storage device of choice. 仍然是首选的辅助存储设备。
- Main advantage over tape: 与磁带相比的主要优势:
- random access vs. sequential. 随机存取与顺序存取。
- Fixed unit of transfer 固定转移单位
- Read/write disk blocks or pages (8K) 读/写磁盘块或页(8K)
- Not “random access” (vs. RAM) 非“随机存取”(与RAM相比)
- Time to retrieve a block depends on location 检索块的时间取决于位置
- Relative placement of blocks on disk has major impact on DBMS performance! 块在磁盘上的相对位置对DBMS性能有重大影响!
Components of a Disk 磁盘组件
- The platters spin (say, 120 rps). 盘片旋转(比如120转)。
- The arm assembly is moved in or out to position a head on a desired track. Tracks under heads make a cylinder (imaginary!). 将臂组件移入或移出,以将头部定位在所需轨道上。头部下方的轨道构成一个圆柱体(想象中的!)。
- Only one head reads/writes at any one time. 一次只能读取/写入一个磁头。
- Block size is a multiple of sector size (which is fixed). 块大小是扇区大小(固定)的倍数。
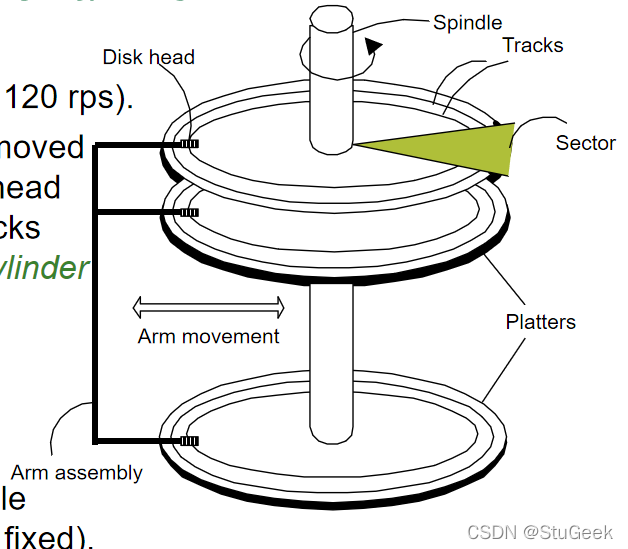
Accessing a Disk Page 访问磁盘页
- Time to access (read/write) a disk block: 访问(读/写)磁盘块的时间
- seek time (moving arms to position disk head on track) 寻道时间(移动臂将磁头定位在磁道上)
- rotational delay (waiting for block to rotate under head) 旋转延迟(等待块在头部下方旋转)
- transfer time (actually moving data to/from disk surface) 传输时间(实际将数据移动到磁盘表面或从磁盘表面移动数据)
- Seek time and rotational delay dominate. 寻道时间和旋转延迟占主导地位。
- Seek time varies from 0 to 10msec 寻道时间从0到10毫秒不等
- Rotational delay varies from 0 to 3msec 旋转延迟从0到3毫秒不等
- Transfer rate around .02msec per 8K block 传输速率约为每8K块0.02毫秒
- Key to lower I/O cost: reduce seek/rotation delays! Hardware vs. software solutions? 降低I/O成本的关键:减少寻道/旋转延迟!硬件与软件解决方案?
Arranging Pages on Disk 在磁盘上排列页面
Next’ block concept:下一个“块”概念:- blocks on same track, followed by 同一磁道上的块,然后是
- blocks on same cylinder, followed by 位于同一柱面上的块,然后是
- blocks on adjacent cylinder 相邻柱面上的块
- Blocks in a file should be arranged sequentially on disk (by `next’), to minimize seek and rotational delay. 文件中的块应在磁盘上按顺序排列(按“下一步”),以最小化寻道和旋转延迟。
- For a sequential scan, pre-fetching several pages at a time is a big win! 对于顺序扫描,一次预取几个页面是一个巨大的胜利!
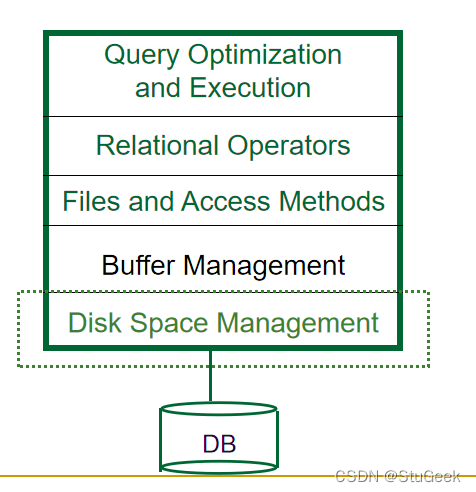
Disk Space Management 磁盘空间管理
- Lowest layer of DBMS, manages space on disk 数据库管理系统的最底层,管理磁盘上的空间
- Higher levels call upon this layer to: 更高级别要求该层
- allocate/de-allocate a page 分配/取消分配页面
- read/write a page 读/写一页
- Request for a sequence of pages best satisfied by pages stored + sequentially on disk! 请求按顺序存储在磁盘上的页面最好满足页面序列!
- Responsibility of disk space manager. 磁盘空间管理器的职责
- Higher levels don’t know how this is done, or how free space is managed. 更高的级别不知道如何做到这一点,也不知道如何管理可用空间
- Though they may make performance assumptions! 尽管他们可能会做出性能假设
- Hence disk space manager should do a decent job. 因此,磁盘空间管理器应该做得很好
Context 环境
Files of Records 文件记录
- Blocks are the interface for I/O, but… 块是I/O的接口,但是…
- Higher levels of DBMS operate on records, and files of records. 更高级别的DBMS对记录和记录文件进行操作。
- FILE: A collection of pages, each containing a collection of records. Must support: 文件:页面的集合,每个页面包含一组记录。必须支持:
- insert/delete/modify record 插入/删除/修改记录
- fetch a particular record (specified using record id) 获取特定记录(使用记录id指定)
- scan all records (possibly with some conditions on the records to be retrieved) 扫描所有记录(可能对要检索的记录具有某些条件)
- Typically implemented as multiple OS “files” 通常实现为多个操作系统“文件”
- Or “raw” disk space 或“原始”磁盘空间
Unordered (Heap) Files 无序(堆)文件
- Collection of records in no particular order. 不按特定顺序收集记录。
- As file shrinks/grows, disk pages (de)allocated 随着文件的缩小/增长,磁盘页(不)被分配
- To support record level operations, we must: 为了支持记录级操作,我们必须:
- keep track of the pages in a file 跟踪文件中的页面
- keep track of free space on pages 跟踪页面上的可用空间
- keep track of the records on a page 跟踪页面上的记录
- There are many alternatives for keeping track of this. 有很多方法可以跟踪这一点。
- We’ll consider two. 我们考虑两个。
Heap File Implemented as a List 作为链表实现的堆文件
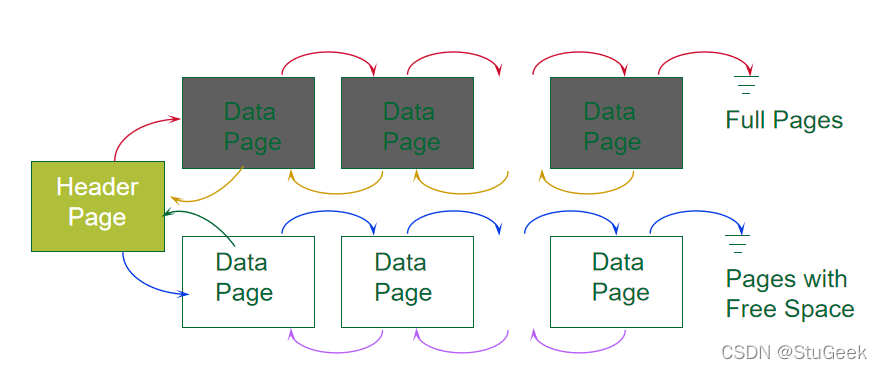
- The header page id and Heap file name must be stored someplace. 头页id和堆文件名必须存储在某个位置。
- Database “catalog” 数据库“目录”
- Each page contains 2 `pointers’ plus data. 每页包含2个“指针”和数据。
- One disadvantage 一个缺点
- Virtually all pages will be on the free list if records are of variable length, i.e., every page may have some free bytes if we like to keep each record in a single page. 如果记录长度可变,则几乎所有页面都将位于空闲列表中,即,如果我们希望将每个记录保留在单个页面中,则每个页面可能都有一些空闲字节。
Heap File Using a Page Directory 使用页面目录堆文件
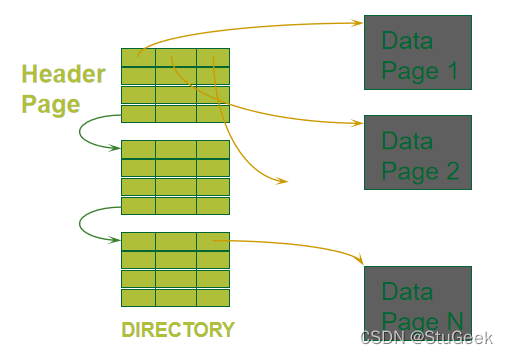
- The directory is itself a collection of pages; each page can hold several entries. 目录本身就是一个页面集合;每页可以容纳多个条目。
- The entry for a page can include the number of free bytes on the page. 页面的条目可以包括页面上的可用字节数。
- To insert a record, we can search the directory to determine which page has enough space to hold the record. 要插入记录,我们可以搜索目录以确定哪个页面有足够的空间来保存记录。
Indexes (a sneak preview) 索引(预览)
- A Heap file allows us to retrieve records: 堆文件允许我们检索记录
- by specifying the rid (record id), or 通过指定rid(记录id),或
- by scanning all records sequentially 按顺序扫描所有记录
- Sometimes, we want to retrieve records by specifying the values in one or more fields, e.g., 有时,我们希望通过在一个或多个字段中指定值来检索记录,例如
- Find all students in the “CS” department 查找“CS”系的所有学生
- Find all students with a gpa > 3 查找gpa>3的所有学生
- Indexes are file structures that enable us to answer such value-based queries efficiently. 索引是一种文件结构,使我们能够高效地回答此类基于值的查询。
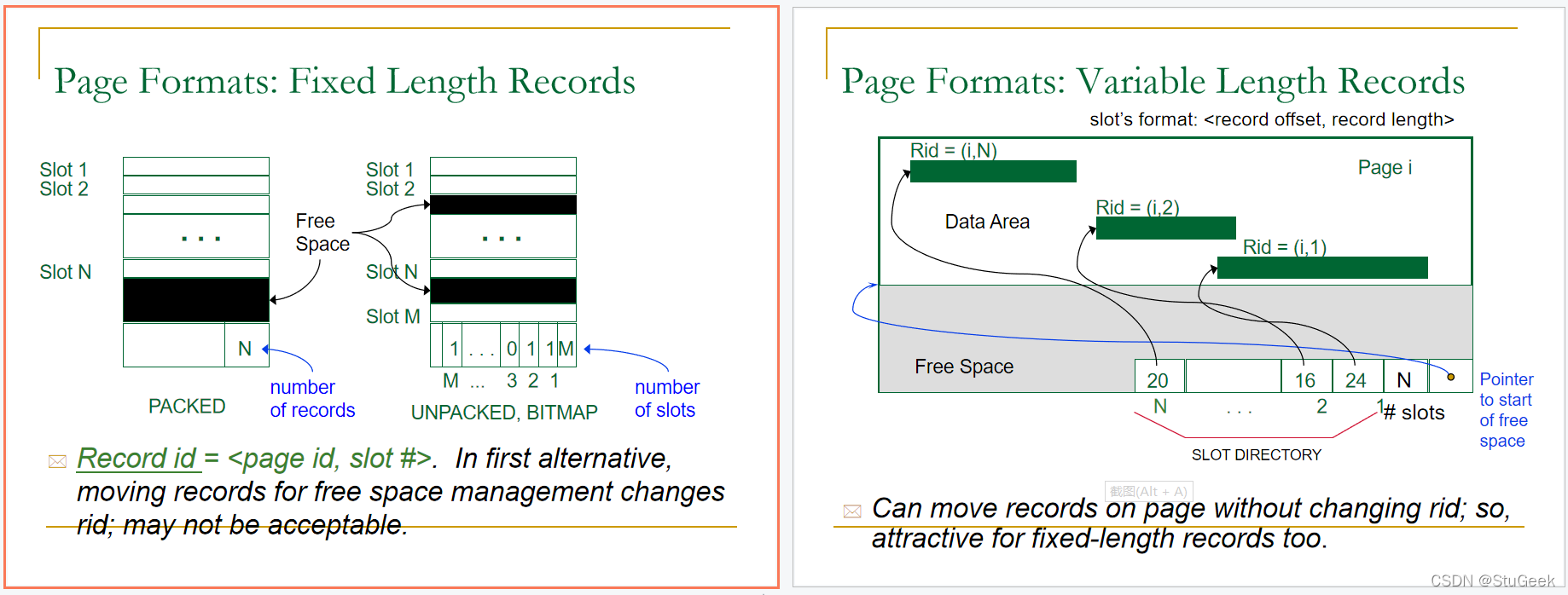
Record Formats: Fixed Length 记录格式:固定长度
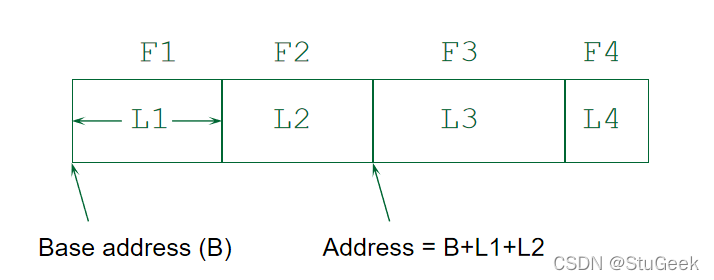
- Information about field types same for all records in a file; stored in system catalogs. 关于文件中所有记录的相同字段类型的信息;存储在系统目录中。
- Finding i’th field done via arithmetic. 通过运算找到第i个字段
Record Formats: Variable Length 记录格式:可变长度
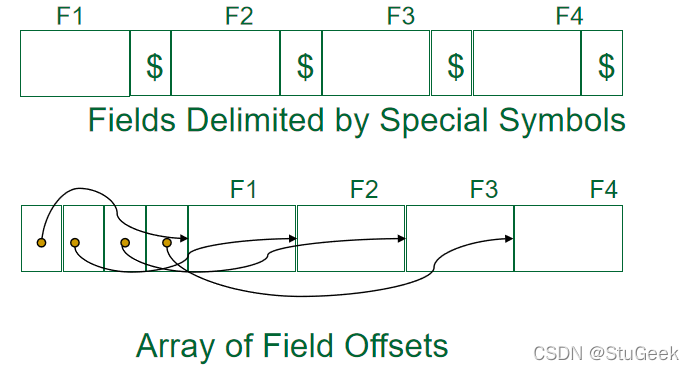
- Two alternative formats (# fields is fixed): 两种可选格式(#字段是固定的)
- Fields Delimited by Special Symbols 由特殊符号分隔的字段
- Array of Field Offsets 字段偏移数组
- Second offers direct access to i’th field, efficient storage of nulls (special don’t know value); small directory overhead. 第二个提供了对第i个字段的直接访问,有效地存储空值(特殊的未知值);目录开销小。






Summary 总结
- Disks provide cheap, non-volatile storage. 磁盘提供廉价的非易失性存储
- Better random access than tape, worse than RAM 随机存取比磁带好,比RAM差
- Arrange data to minimize seek and rotation delays. 安排数据以最小化寻道和旋转延迟
- Depends on workload! 取决于工作量
- Buffer manager brings pages into RAM. 缓冲区管理器将页面带入RAM
- Page pinned in RAM until released by requestor. 页面固定在RAM中,直到请求者释放
- Dirty pages written to disk when frame replaced (sometime after requestor unpins the page). 当帧被替换时(请求者解除页面锁定后的某个时间),脏页被写入磁盘
- Choice of frame to replace based on replacement policy. 根据更换策略选择要更换的帧
- Tries to pre-fetch several pages at a time. 尝试一次预取几页
- DBMS vs. OS File Support DBMS与OS文件支持
- DBMS needs non-default features DBMS需要非默认特性
- Careful timing of writes, control over prefetch 仔细安排写入时间,控制预取
- Variable length record format 可变长度记录格式
- Direct access to i’th field and null values. 直接访问第i个字段和空值
- Slotted page format 分槽页格式
- Variable length records and intra-page reorg 可变长度记录和页面内重新排序
- DBMS “File” tracks collection of pages, records within each. DBMS“文件”跟踪每个文件中的页面和记录的集合
- Pages with free space identified using linked list or directory structure 使用链表或目录结构标识具有可用空间的页面
- Indexes support efficient retrieval of records based on the values in some fields. 索引支持根据某些字段中的值高效检索记录
- Catalog relations store information about relations, indexes and views. 目录关系存储有关关系、索引和视图的信息
lec4 查询语言 SQL: The Query Language
回顾
- Relational Algebra (Operational Semantics) 关系代数(操作语义)
- Given a query, how to mix and match the relational algebra operators to answer it 给定一个查询,如何混合和匹配关系代数运算符来解答它
- Used for query optimization 用于查询优化
- Relational Calculus (Declarative Semantics) 关系演算(说明语义)
- Given a query, what do I want my answer set to include? 给定一个查询,我希望我的答案集包括什么?
- Algebra and safe calculus are simple and powerful models for query languages for relational model 代数和安全演算是关系模式查询语言的简单而强大的模型
- Have same expressive power 有同样的表现力
- SQL can express every query that is expressible in relational algebra/calculus. (and more) SQL可以表达每一个可以用关系代数/演算表达的查询。(及更多)
Relational Query Languages 关系查询语言
- Two sublanguages: 两个子语言:
- DDL – Data Definition Language 数据定义语言
- Define and modify schema (at all 3 levels) 定义和修改架构(在所有3个级别)
- DML – Data Manipulation Language 数据操作语言
- Queries can be written intuitively. 可以直观地编写查询。
- DDL – Data Definition Language 数据定义语言
- DBMS is responsible for efficient evaluation. DBMS负责有效的评估。
- The key: precise semantics for relational queries. 关键:关系查询的精确语义。
- Optimizer can re-order operations 优化器可以重新排序操作
- Won’t affect query answer. 不会影响查询答案。
- Choices driven by “cost model” 由“成本模型”驱动的选择
The SQL Query Language SQL查询语言
P97
- The most widely used relational query language. 最广泛使用的关系查询语言
- Standardized 标准化
- (although most systems add their own “special sauce” – including PostgreSQL) 尽管大多数系统都添加了自己的“特殊角色”——包括PostgreSQL
- We will study SQL92 – a basic subset 我们将研究SQL92——一个基本子集
数据库例子
P98
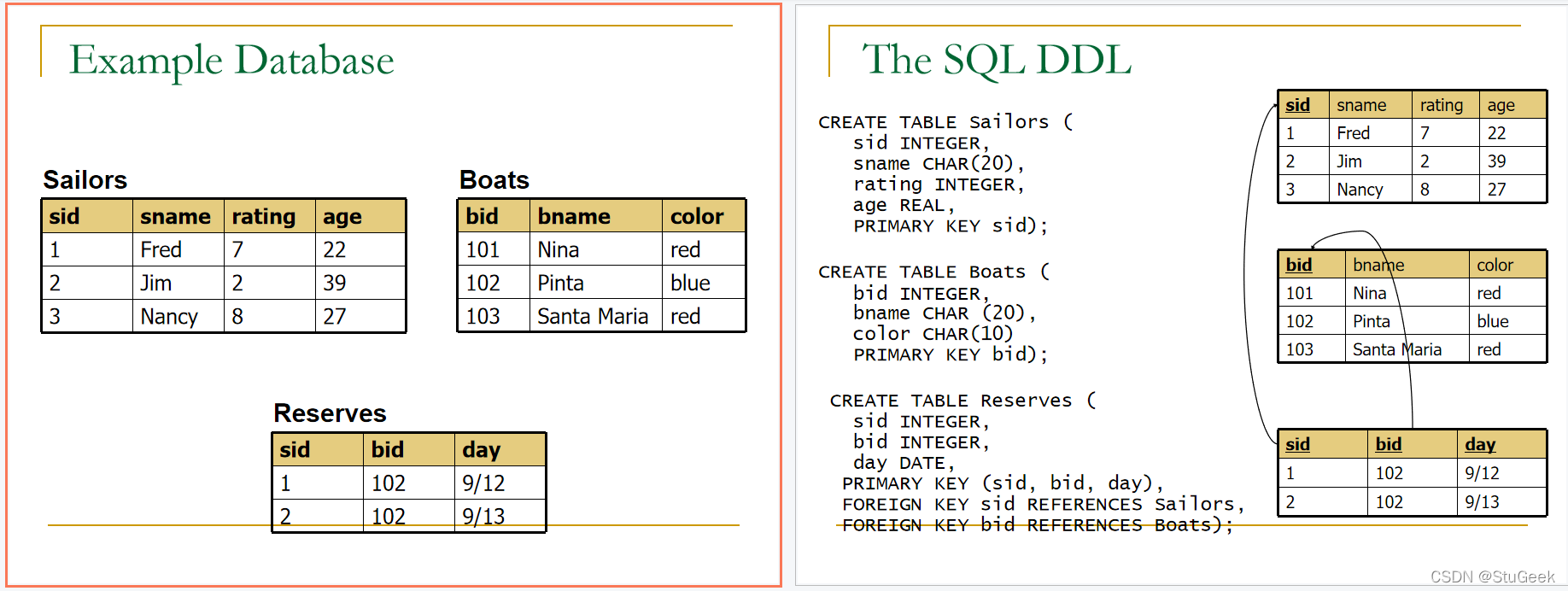







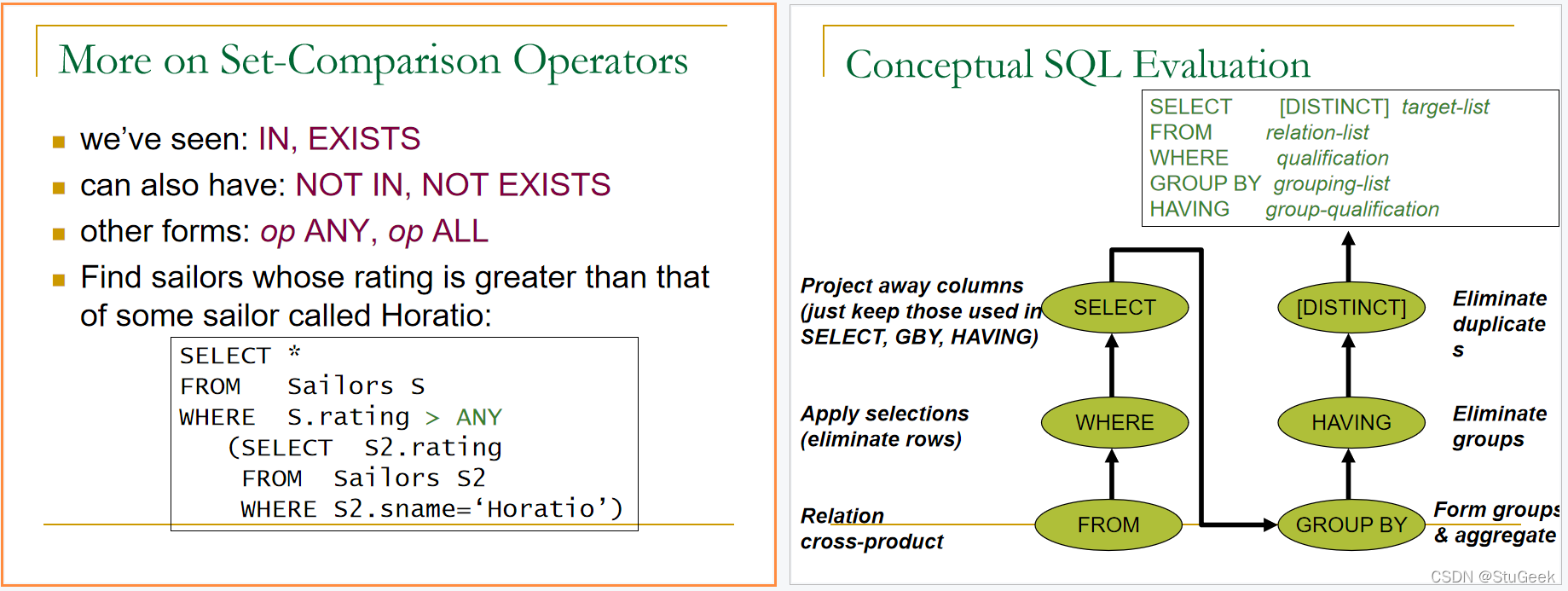



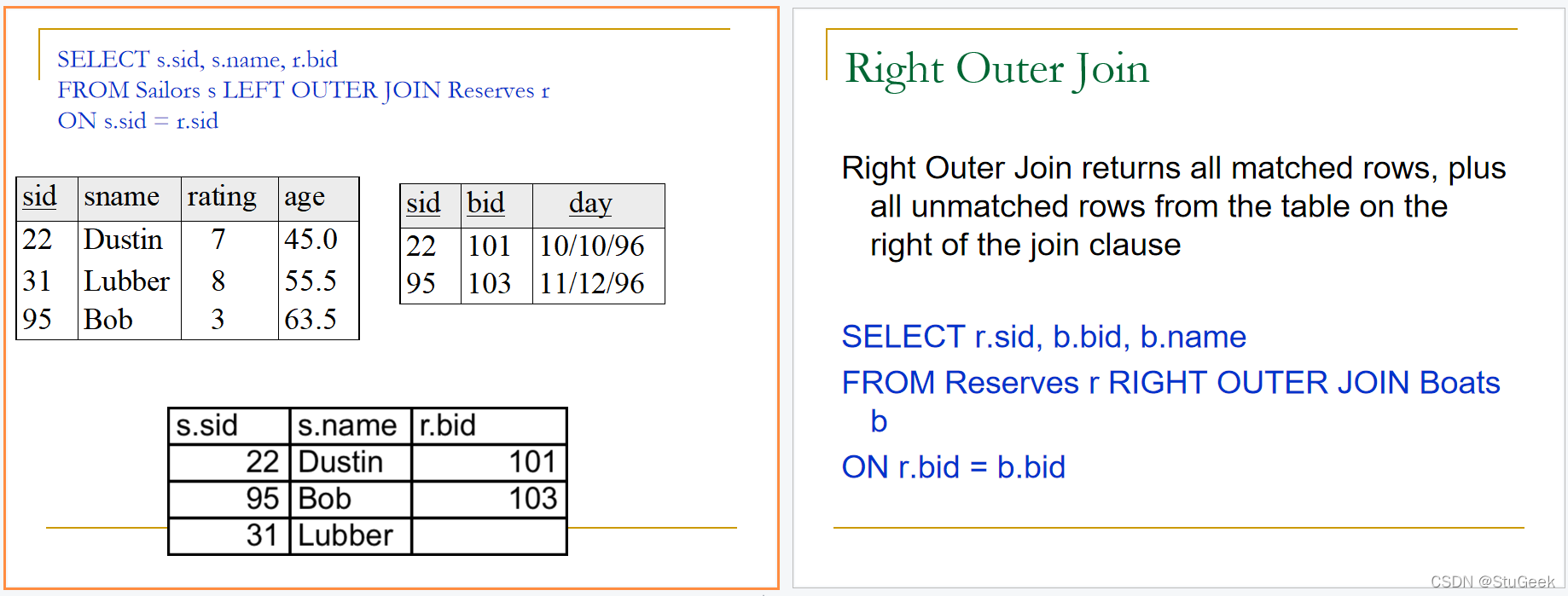




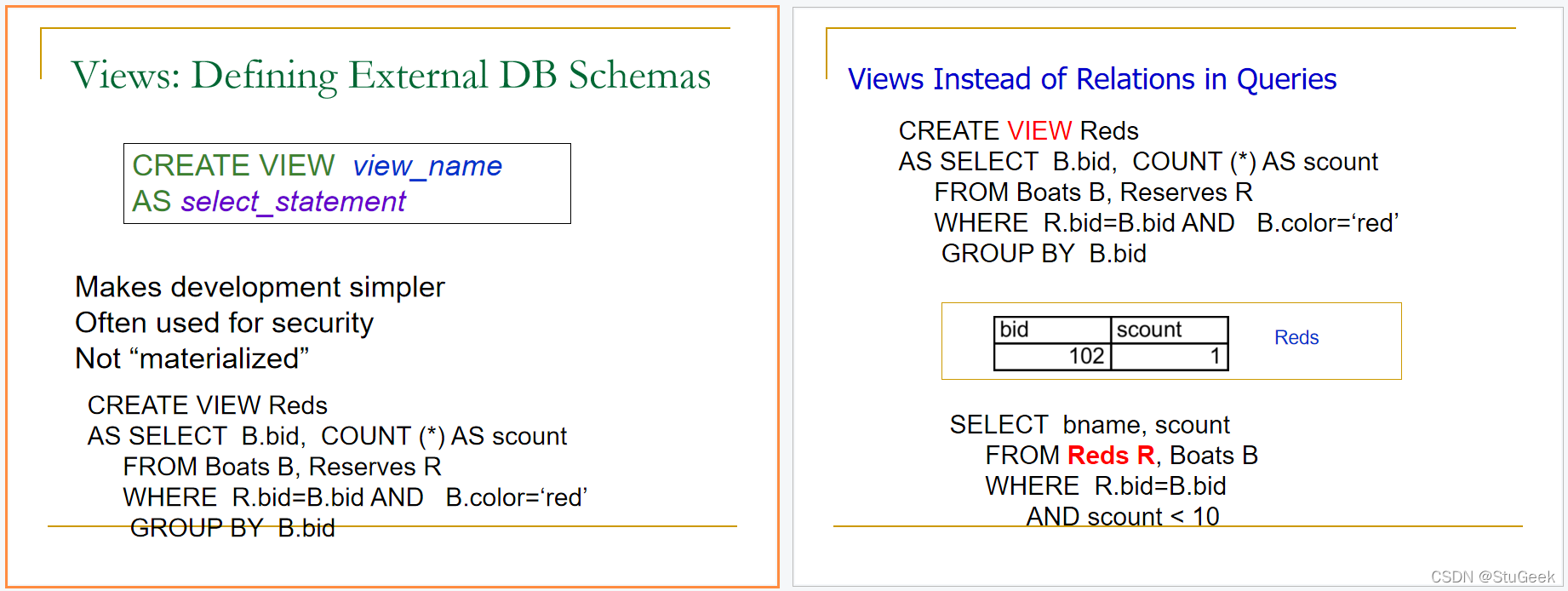
Conceptual Evaluation 概念评估
- The cross-product of relation-list is computed, tuples that fail qualification are discarded, `unnecessary’ fields are deleted, and the remaining tuples are partitioned into groups by the value of attributes in grouping-list. 计算关系列表的叉积,丢弃不符合要求的元组,删除“不必要”字段,并根据分组列表中的属性值将剩余元组划分为组。
- One answer tuple is generated per qualifying group. 每个符合条件的组生成一个答案元组。

Conceptual Evaluation 概念评估
- Form groups as before. 像以前一样分组。
- The group-qualification is then applied to eliminate some groups. 然后应用组限定来消除某些组。
- Expressions in group-qualification must have a single value per group! 组限定中的表达式每个组必须有一个值!
- That is, attributes in group-qualification must be arguments of an aggregate op or must also appear in the grouping-list. (SQL does not exploit primary key semantics here!) 也就是说,组限定中的属性必须是聚合op的参数,或者也必须出现在分组列表中。(SQL在此不利用主键语义!)
- One answer tuple is generated per qualifying group. 每个符合条件的组生成一个答案元组。


Two more important topics 还有两个重要的话题
- Constraints 约束条件
- SQL embedded in other languages 嵌入其他语言的SQL
Integrity Constraints (Review) 完整性约束(回顾)
- An IC describes conditions that every legal instance of a relation must satisfy. IC描述了关系的每个合法实例必须满足的条件。
- Inserts/deletes/updates that violate IC’s are disallowed. 不允许违反IC的插入/删除/更新。
- Can ensure application semantics (e.g., sid is a key), or prevent inconsistencies (e.g., sname has to be a string, age must be < 200) 可以确保应用程序语义(例如,sid是一个键),或防止不一致(
